

A Practical Guide to Data Trees in Grasshopper
The what, why and how of data-trees in Grasshopper


This article is part of the Designing with Numbers series, a continuation of the Geometry Basics series. Together, they explore how computational design is shaped first by geometry, then by numbers.
Part 1 : It’s not always about geometry, numbers matter too.
Part 2 : How Curve Parameters Give You More Control in Grasshopper
Part 3 : How Surface Parameters Turn Geometry Into Information
Part 5 : Using Logic to Guide Your Models in Computational Design
Part 6 : A Practical Guide to Data Trees in Grasshopper (This article)
It was just after lunch when Jay called me over.
He’d been working on a script that creates retaining walls in Revit from a line in Rhino. It’s useful stuff, since all someone has to do now is draw a line and fill in some parameters. It’s something we’d been meaning to automate for a while but just never had the time.
He looked relieved as I walked over. “I finally got it working, but it doesn’t work for the whole model” he said, zooming into Grasshopper. “At least, all they have to do is copy this block of code for every wall. It’s still better than modelling it manually, I guess”
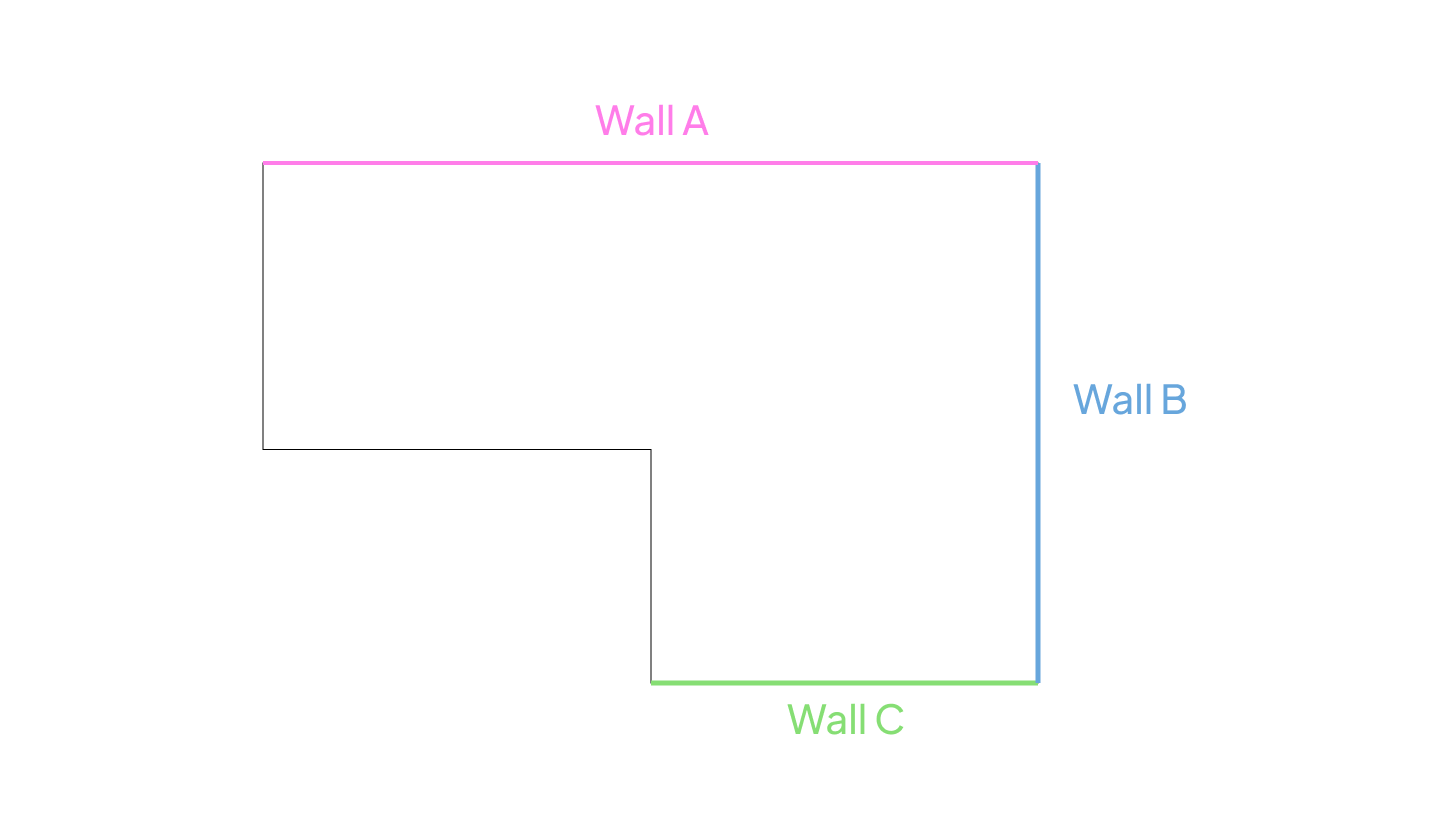
Jay hoped I could help him make the script work for the entire model without having to copy and paste the block dozens of times.
And there was a way. After a quick look, I noticed his script only accepted a single line and had flatten components everywhere, which messed up his data structure when he tried multiple lines.
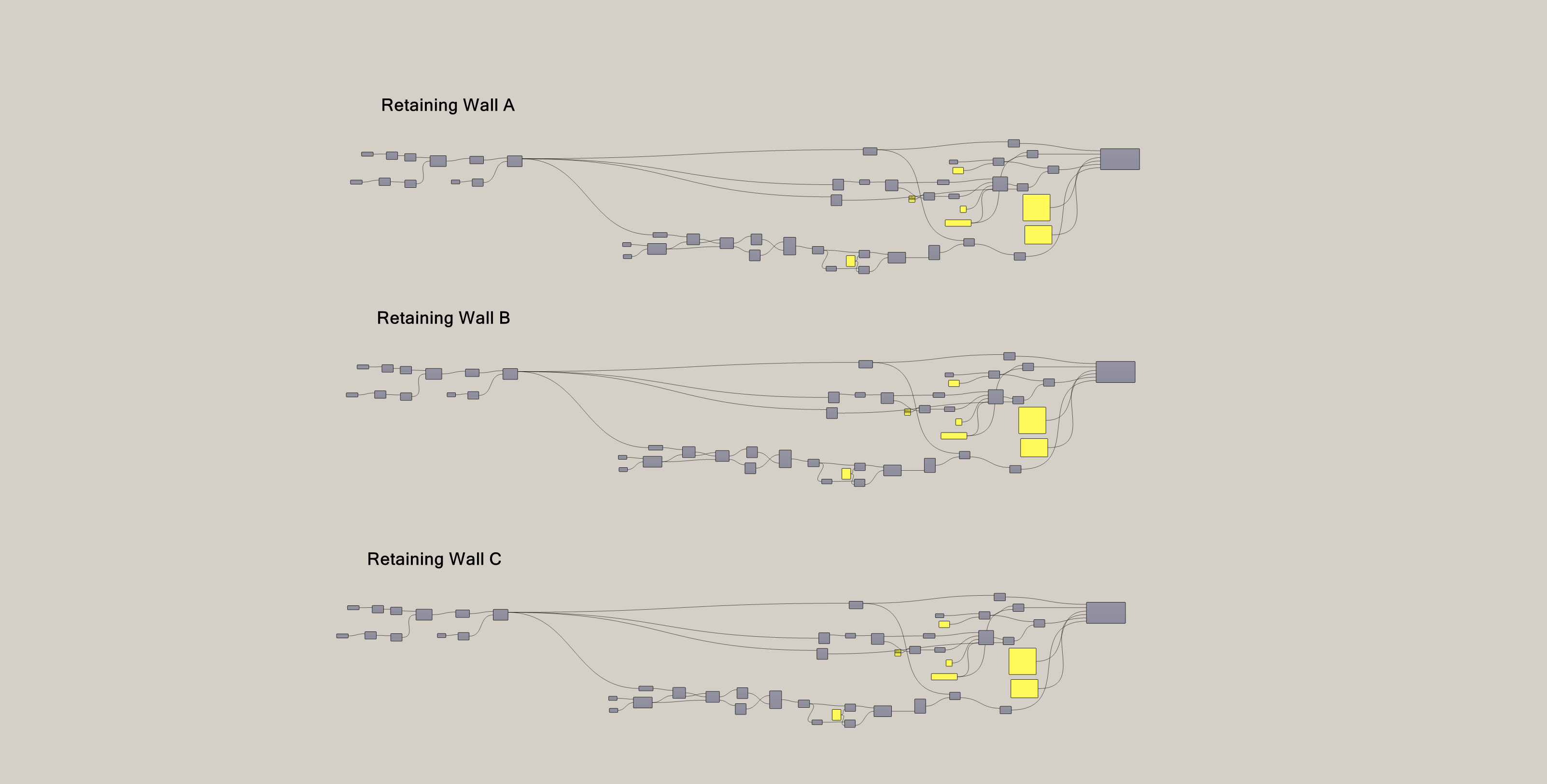
Thankfully, the logic was simple and worked well. We just needed to modify the script to accept a data tree instead of a single item.
A graft here, a shift path there, and the same logic now worked for the entire model instead of just one wall.
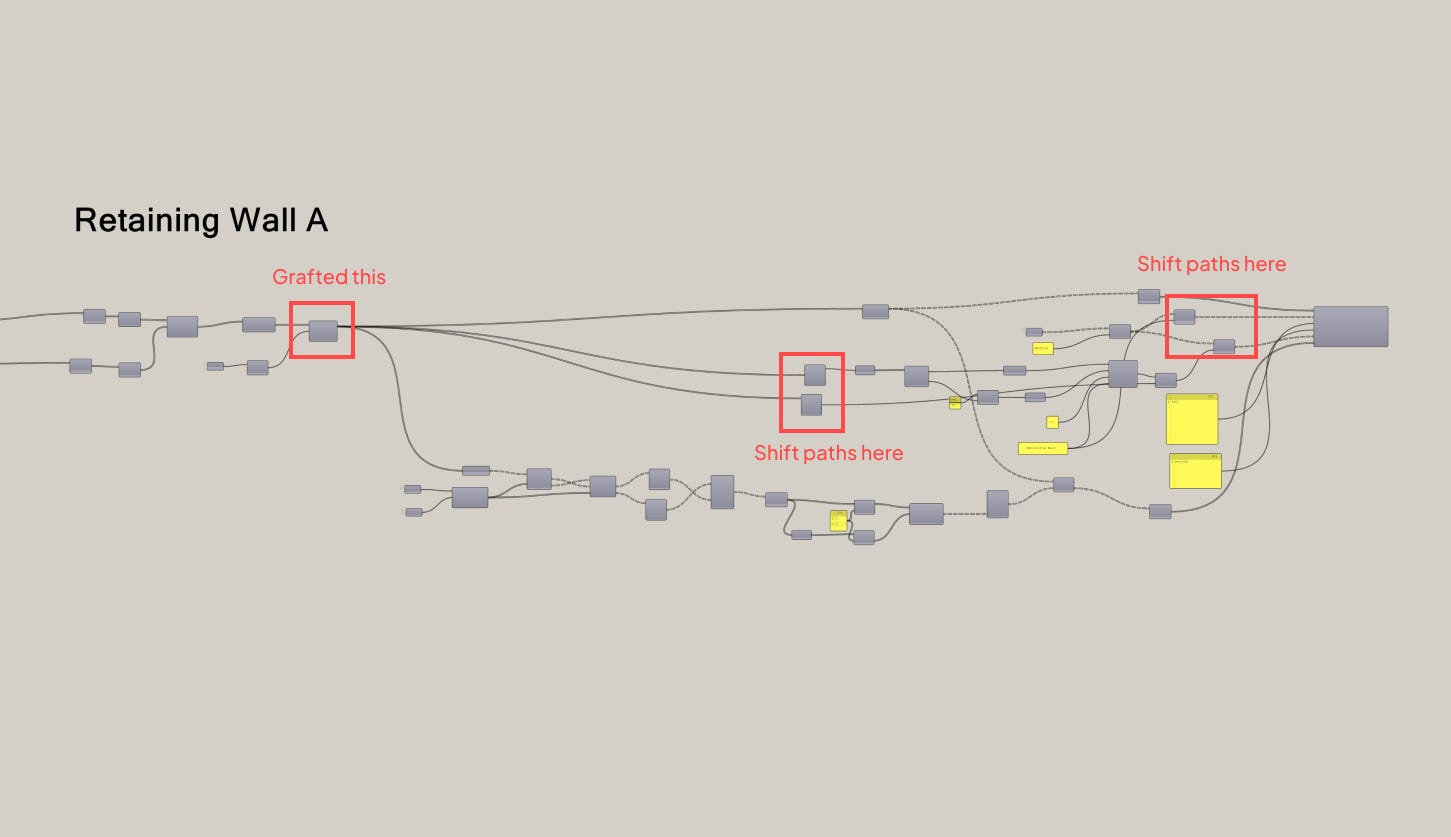
Jay looked at me, surprised. “That’s it?”
We got lucky this time because the logic was simple. Usually, scaling up like this requires more thought. Even though we removed the duplicated components by using data trees, the workflow was now more complex. If the tree structure changed, it could break. Copy-pasting was less elegant but more robust.
So like everything else in computational design, it’s a trade-off. Personally, I prefer a single workflow with a more complex data tree over many disconnected ones. It’s easier to maintain and scale. You can always adjust a data tree but you can’t merge ten slightly different workflows without wanting to hurt someone.
But to even make this decision, you need to understand how to structure your data in the first place.
That’s where today’s article comes in. We’re going to look into using data structures (primarily data-trees) in Grasshopper. And don’t worry I promise to keep it practical.
What are data structures in Grasshopper?
Most people learn Grasshopper by connecting components and seeing what happens. Few worry about how the data moves between those components. It’s partly Grasshopper’s fault because even if you have mismatched data structures, your script will still run. You might get a weird results but you won’t get an error. Unlike Dynamo, Grasshopper is more forgiving which can be a bad and a good thing.
Like most things in Grasshopper, data structures are simple to understand but harder to put into practice.
I want to clarify something before we move on.
You’ll see throughout this article that I use the words “data structure” and “data tree”. While people use them interchangeably, they do mean different things.
A data-tree is Grasshopper’s way of managing large amounts of data. There are some rules and ways Grasshopper uses a data-tree to run it’s components.
“Data structure,” however, is a broader term that also includes how you manage items and lists.
When most people say “data structures in Grasshopper”, they normally refer to data-trees.
But regardless of the definition, this is a technically complex topic to write about. It’s also a topic that’s been written many times by other people. But most people don’t write about how to use data-trees.
So, that’s my goal with this article, to show you some common ways I use data-trees and how I think about structuring my data in Grasshopper. But first, let me just briefly explain data structures in Grasshopper.
Data Structures in Grasshopper
There are three tiers of data in Grasshopper. You have the item, list and tree.
Item
This is the simplest structure, a single unit of data. This could be a curve, surface or even a generic data object
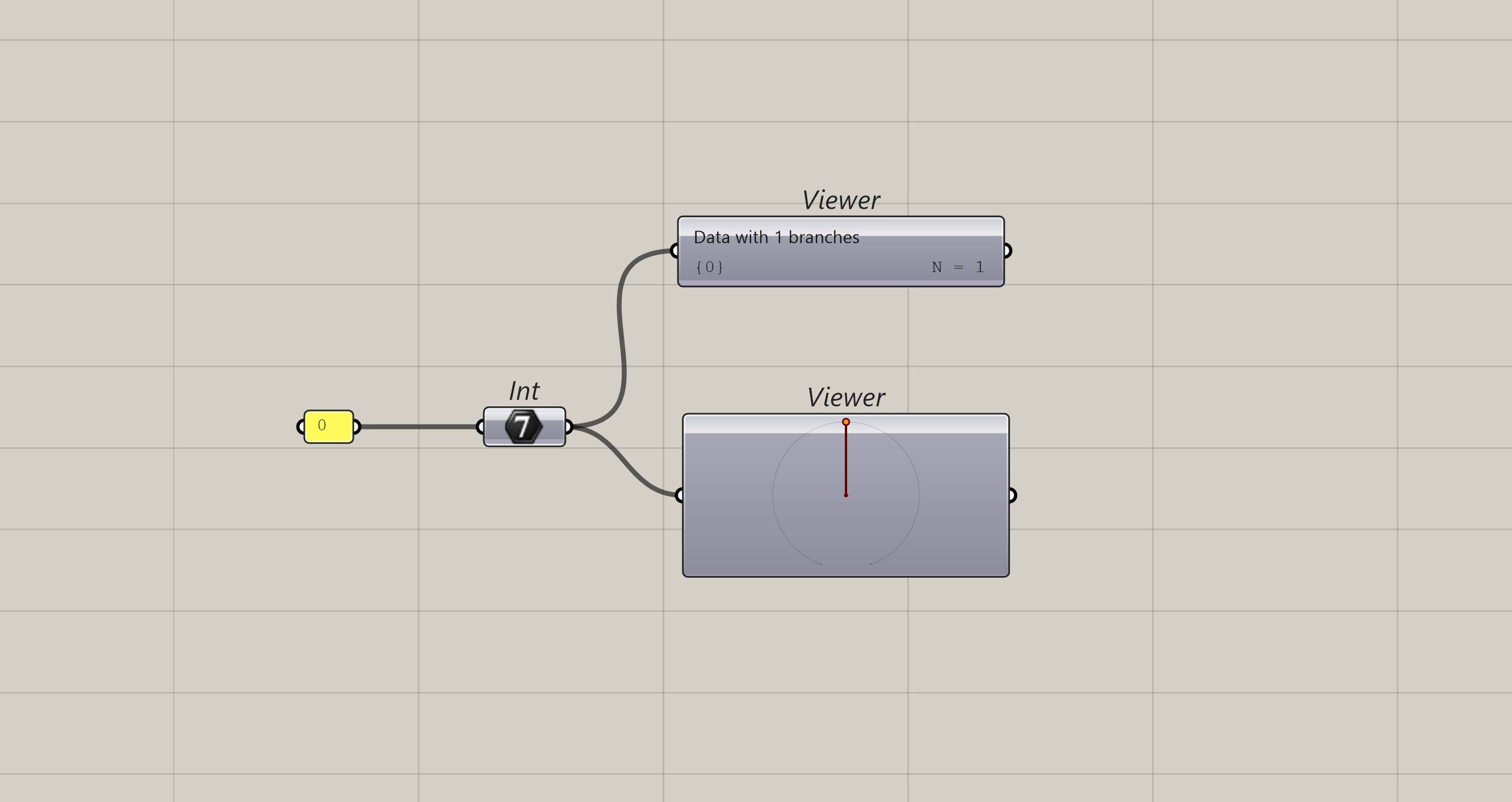
List
Then we go a step up and we have a list of items. You start introducing more complexity now because you have to manage the order of the list and/or it’s length.
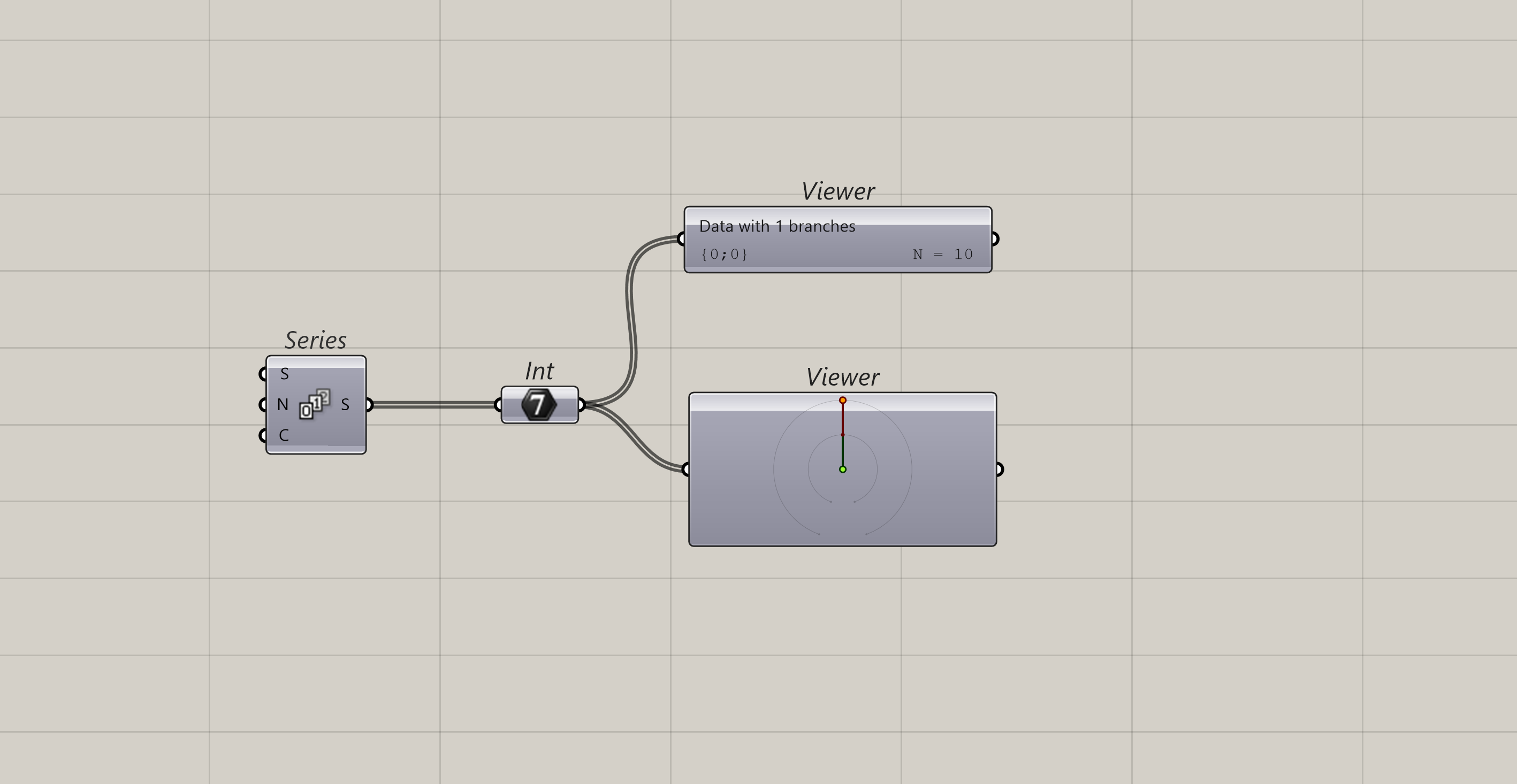
Tree
Finally, you have the notorious trees which has been called a table or a matrix. Or as I like to think of it, a list within lists.
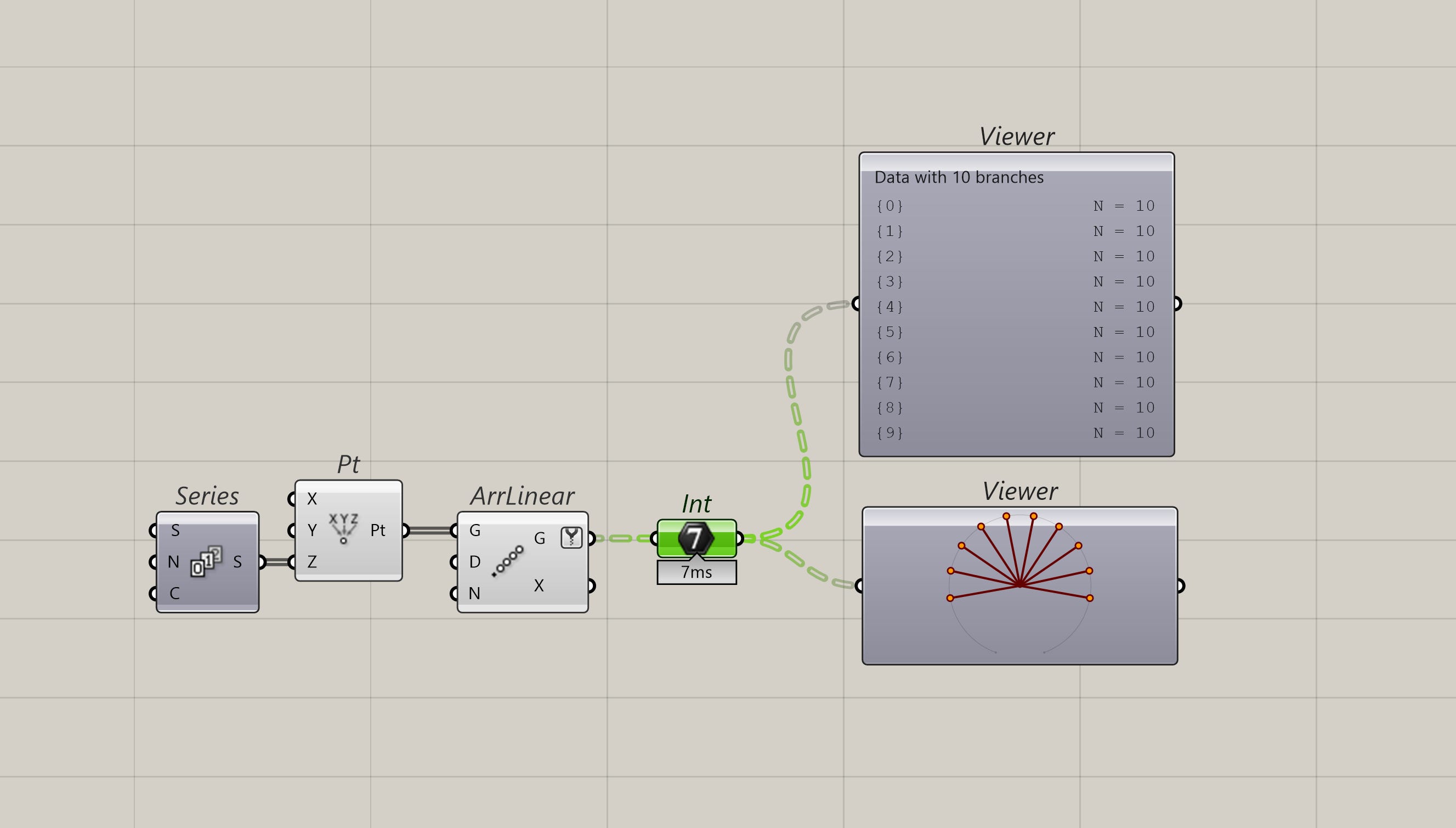
You can also nest as many lists within lists as you want. This is typically referred to as the depth of the tree.
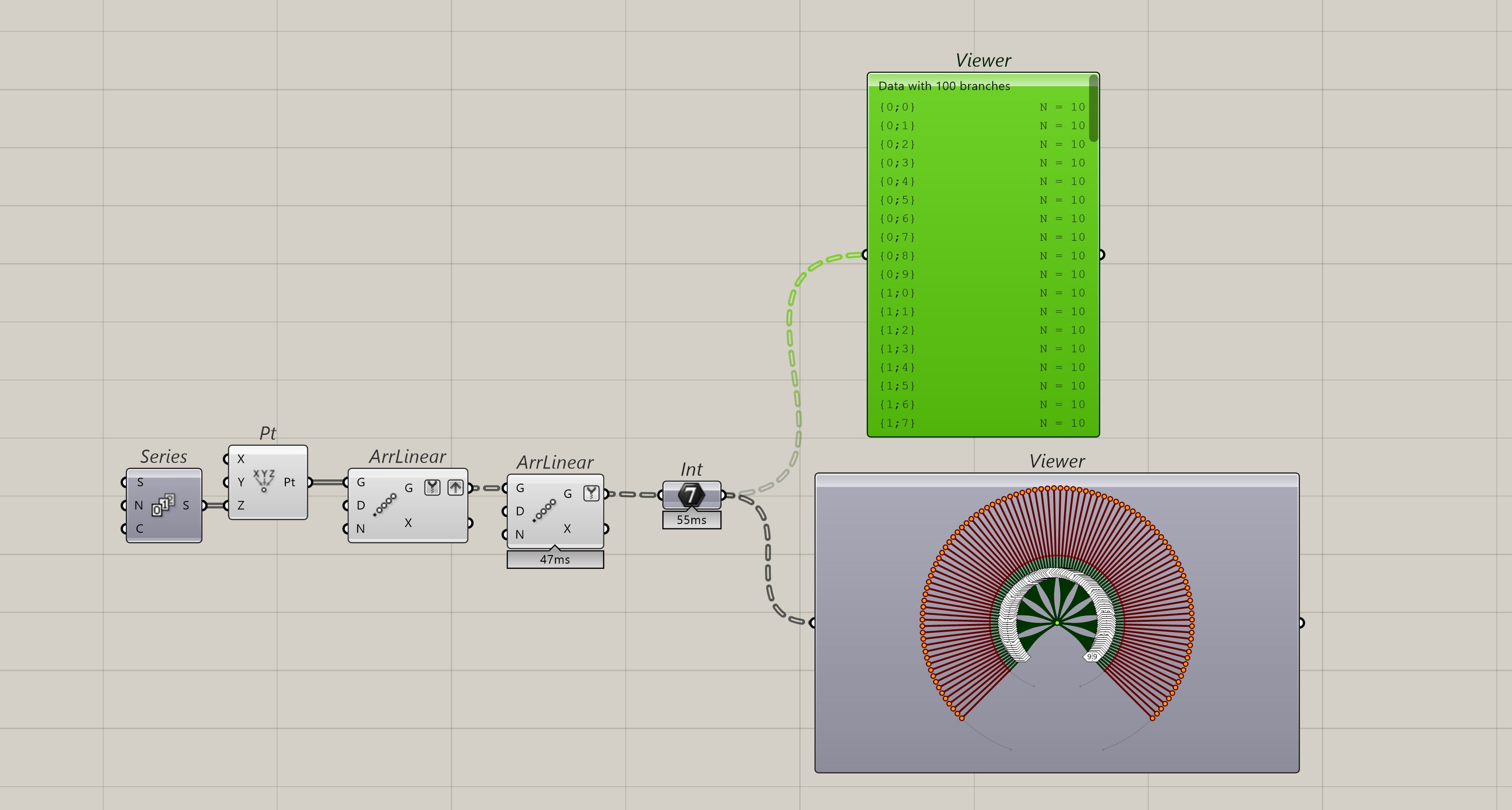
Note: I typically don’t recommend using the tree view in the param viewer component because it’s not helpful. I am just using it here to give you a visual of what trees are.
Okay, that’s it, in terms of what data-trees in Grasshopper are. Again, it’s much easier to explain what it is than to use them in practice.
If you do want a more in-depth explanation, I have found this video to be the best explanation of what data-trees are.
But as great as any explanation is, experience is the key to mastering data trees. Use Grasshopper more and you’ll inevitably come across data-trees. When you do, don’t run away from them. Don’t copy and paste components just because it’s easier. Try to sit and wrangle with them to gain more experience.
They can seem overwhelming at the start because they are abstract but data-trees is a vital data structure that is built into Grasshopper and you won’t get very far if you don’t know how to use them.
That being said, let’s look at some of the ways I work with data-trees.
Data Trees in Action
The usefulness of working with data-trees comes when the data or geometry is complicated. It’s partly why teaching people about it is so hard because even just learning the context can be difficult.
So as you go through these examples, don’t dwell on the geometry or data too much. Focus on how I’m manipulating the data-trees to my advantage.
Note: I’ll be writing about data-trees in-depth here. So, it may feel confusing/overwhelming, especially if you’re new to Grasshopper. If you’re not familiar with data-trees, I recommend watching this video before continuing.
You can always come back here when you’re more experienced too.
Merging shatter results
In a previous article on using logic to guide your models, I showed how I use logical operations to merge the results from the shatter component. In that example, I was showing the use of logical operators. This time, let’s look at it from a data point of view.
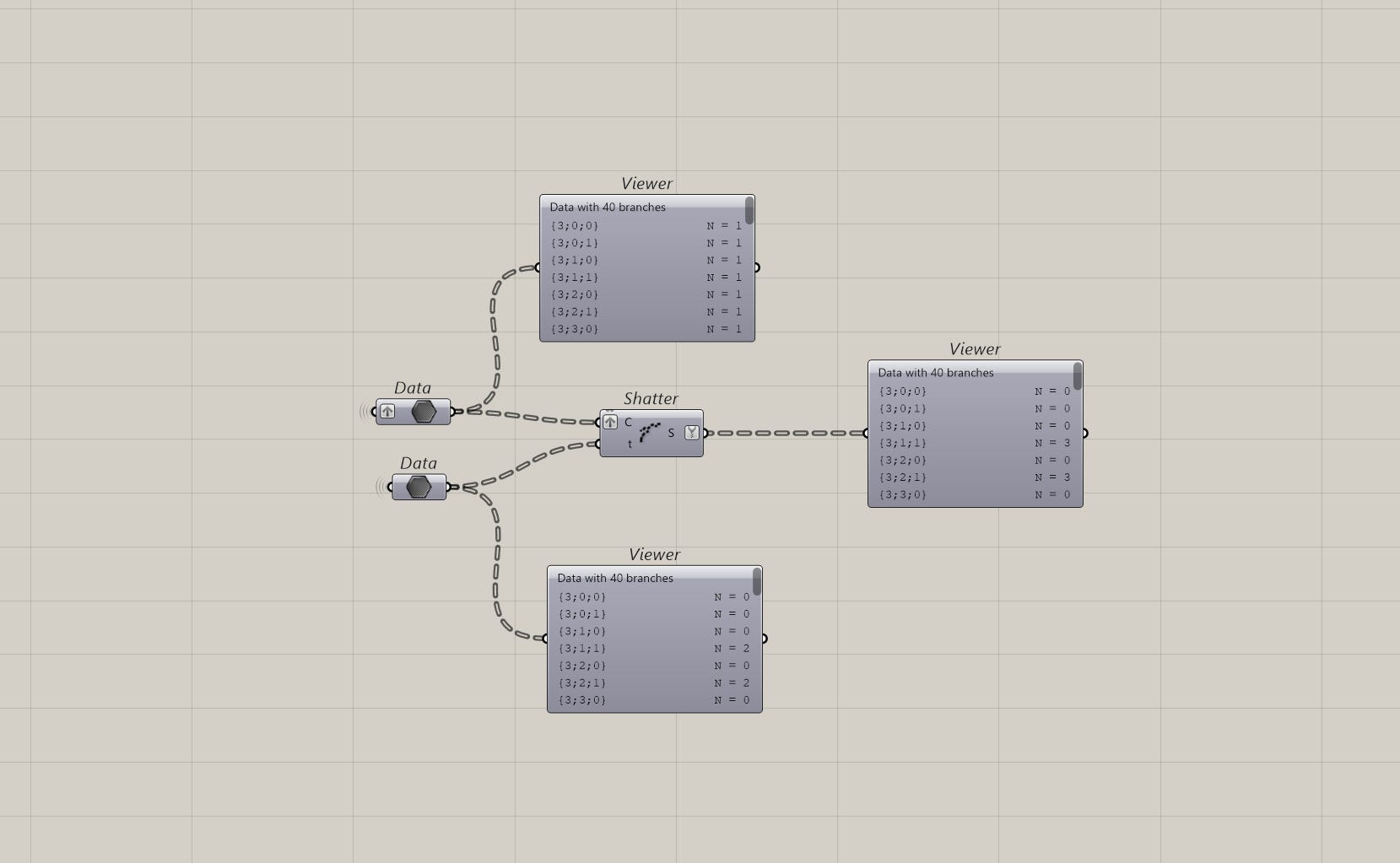
For example, I have a data-tree of curves and a list of points that may or may not be close to the curves. I want to split the curves if the point is close enough. I’ll first check it’s distance and if it’s close enough, I’ll shatter them.
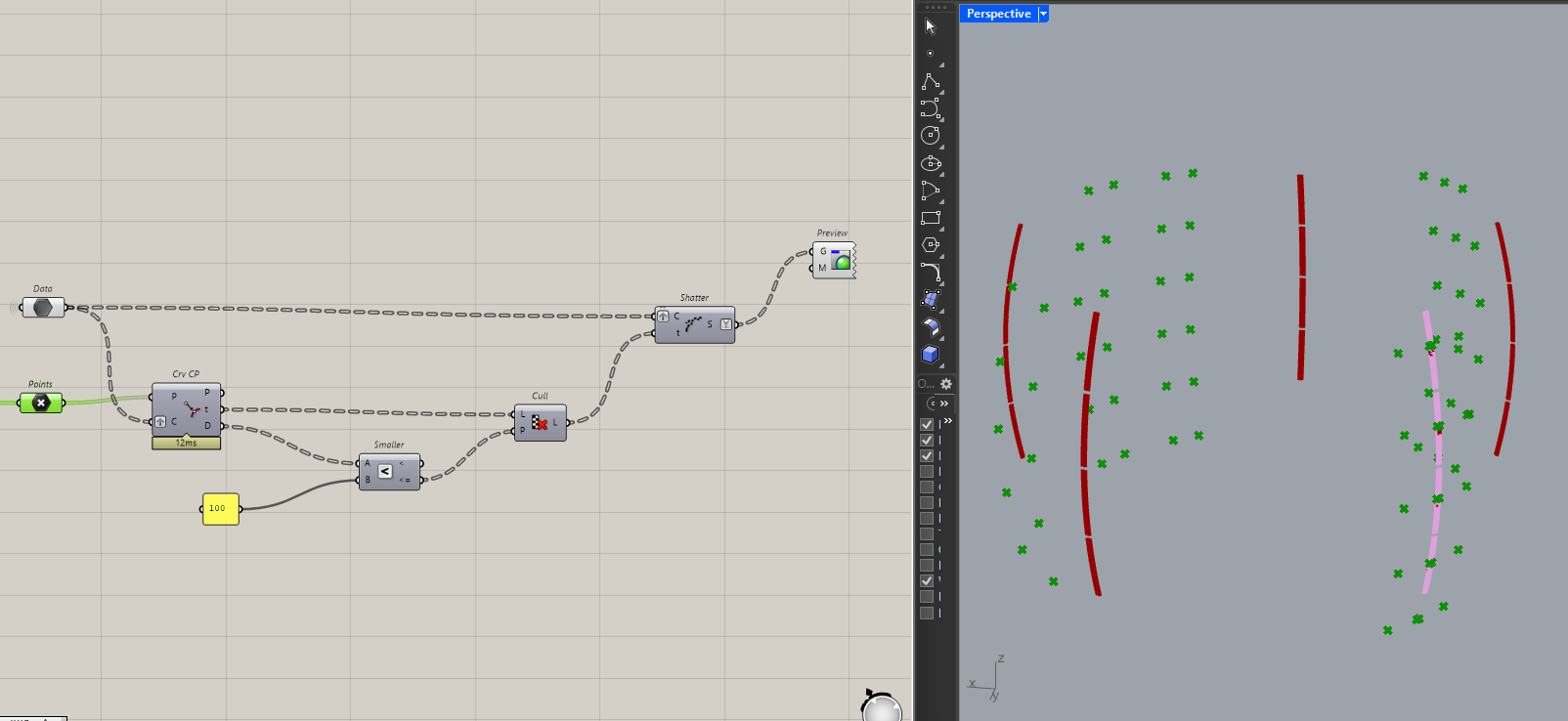
The problem here is, if you pass in a null or an empty value into the shatter component, you won’t get any results back.
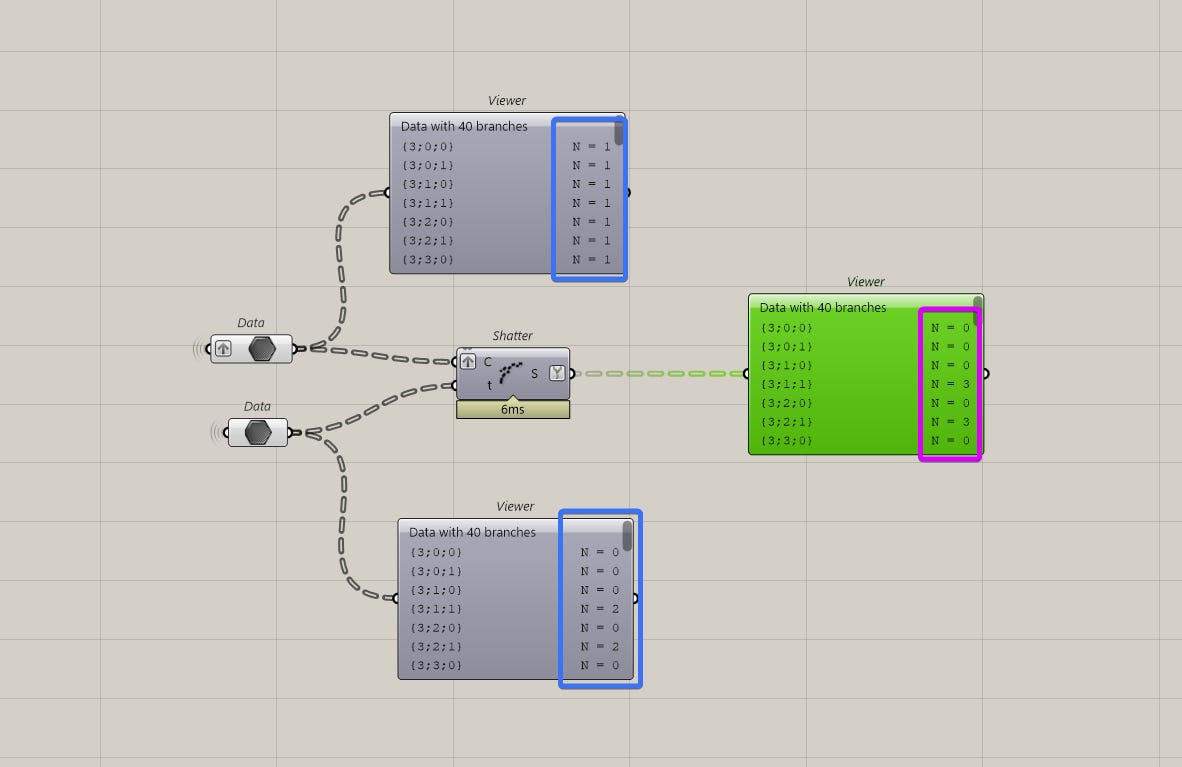
This might not seem like a big deal but it’s much cleaner to have all my curves (shattered and non-shattered) in a single data stream. That way, I don’t have to manage multiple streams later on.
You have two options to solve this, separate out the relevant data before and pass in only the correct curves to be shattered and merge them back. Or find a way to merge them back after the shatter.
I prefer the second option because I can let the shatter component handle the relevant intersections and use the paths of the data-trees merge them back.
To do this, I use the clean tree component with the remove empty option set to true. This gives me all the shattered curves only.
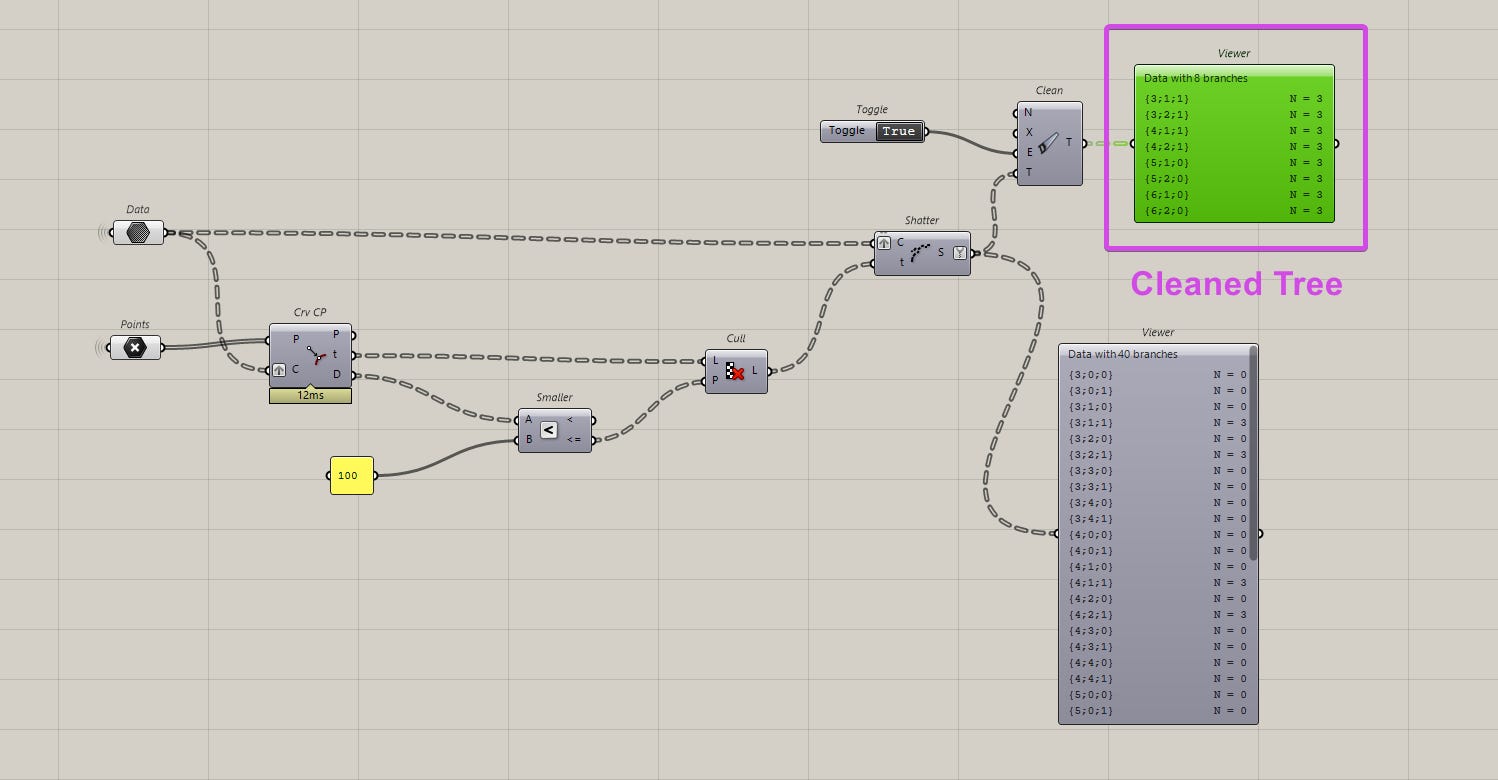
Alright, here is where it gets tricky. What I do next, is get the paths of this cleaned tree and split the original tree of curves by it.
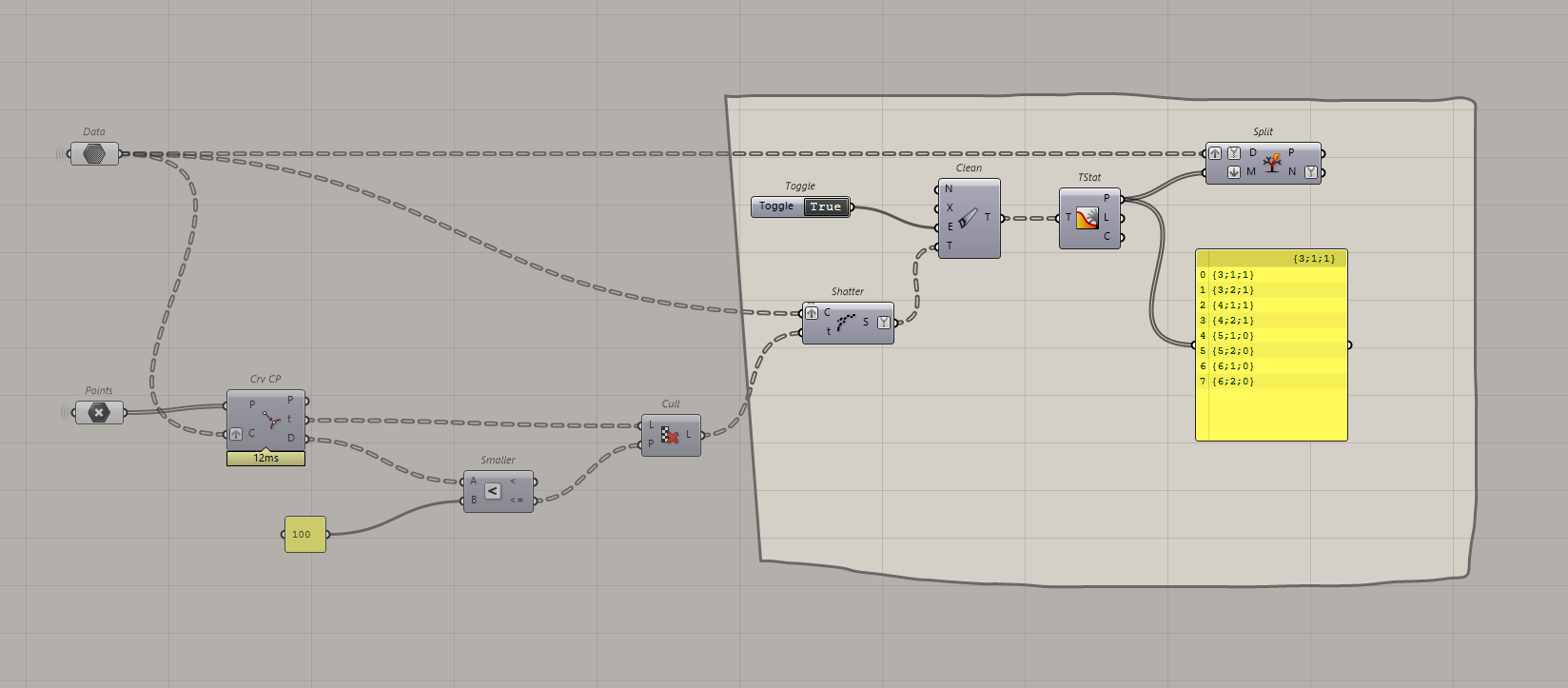
Because I know they share the same tree structure, I can tell Grasshopper to split the tree based on the paths.
Note: If this seems confusing, pause here and let the last sentence sink in.
Paths are pointers to the data in the tree. So getting the path from the clean tree is like telling someone where to find the books in a library but not actually giving them the books.
Using the paths to split the tree means I can now merge the cleaned shattered tree with the original tree.
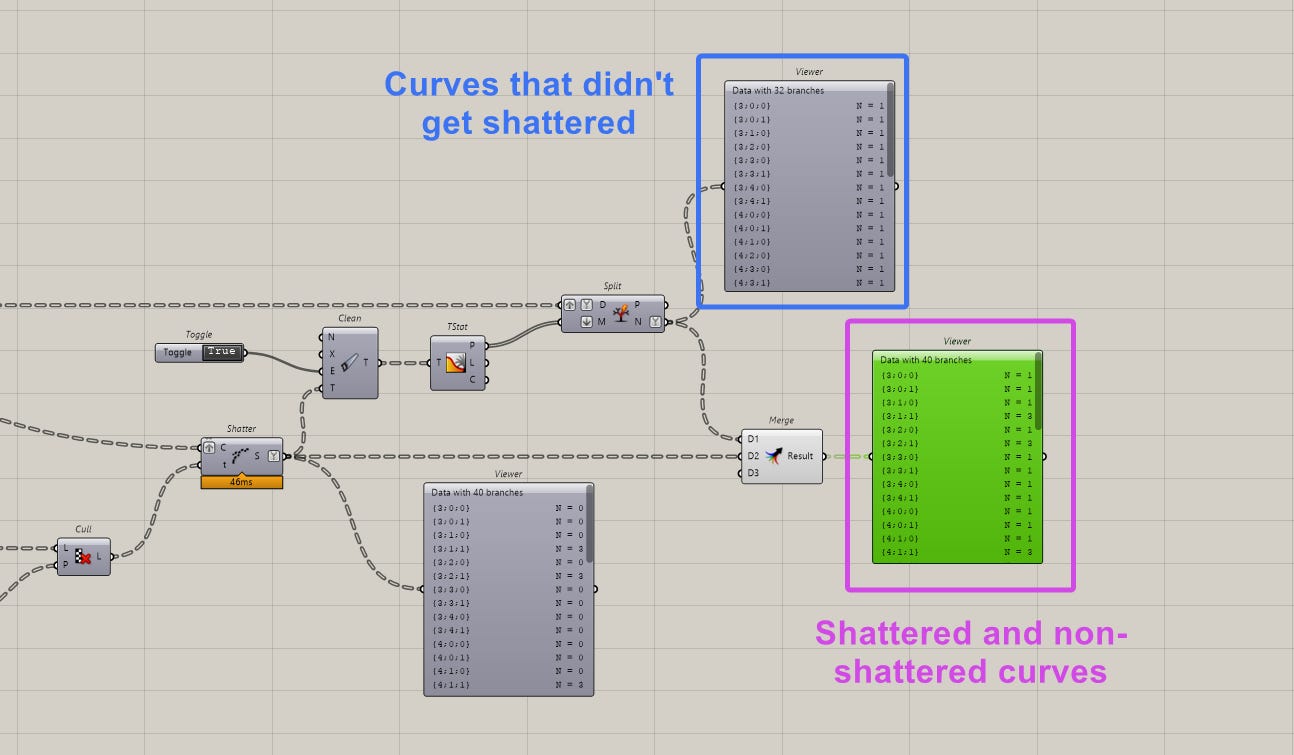
I know this might be a lot to process but it’s actually only 4 components after the shatter operation. The key here is to understand what the paths to the tree represent.
If you can understand this, you can actually use this technique regardless of your tree depth.
Grouping to reduce tree complexity
Okay, sometimes your data-tree structure can get too complex for the geometry operation you need.
One answer to this, is to reduce your tree complexity. You can use groups to do that. Because they essentially let you treat a list of data as a single item. Which means a branch of items can be treated like a list.
Here’s an example. I have a data-tree of vertical members. I need to create some diagonal lines between them but If there’s a “box” there, I don’t want to create the diagonal members. In the real world, these are “bracing” members between columns and the “boxes” are windows. I don’t want to have members go through my windows.
The challenge here is to keep the vertical members to create the diagonals but somehow find a way to avoid the boxes.
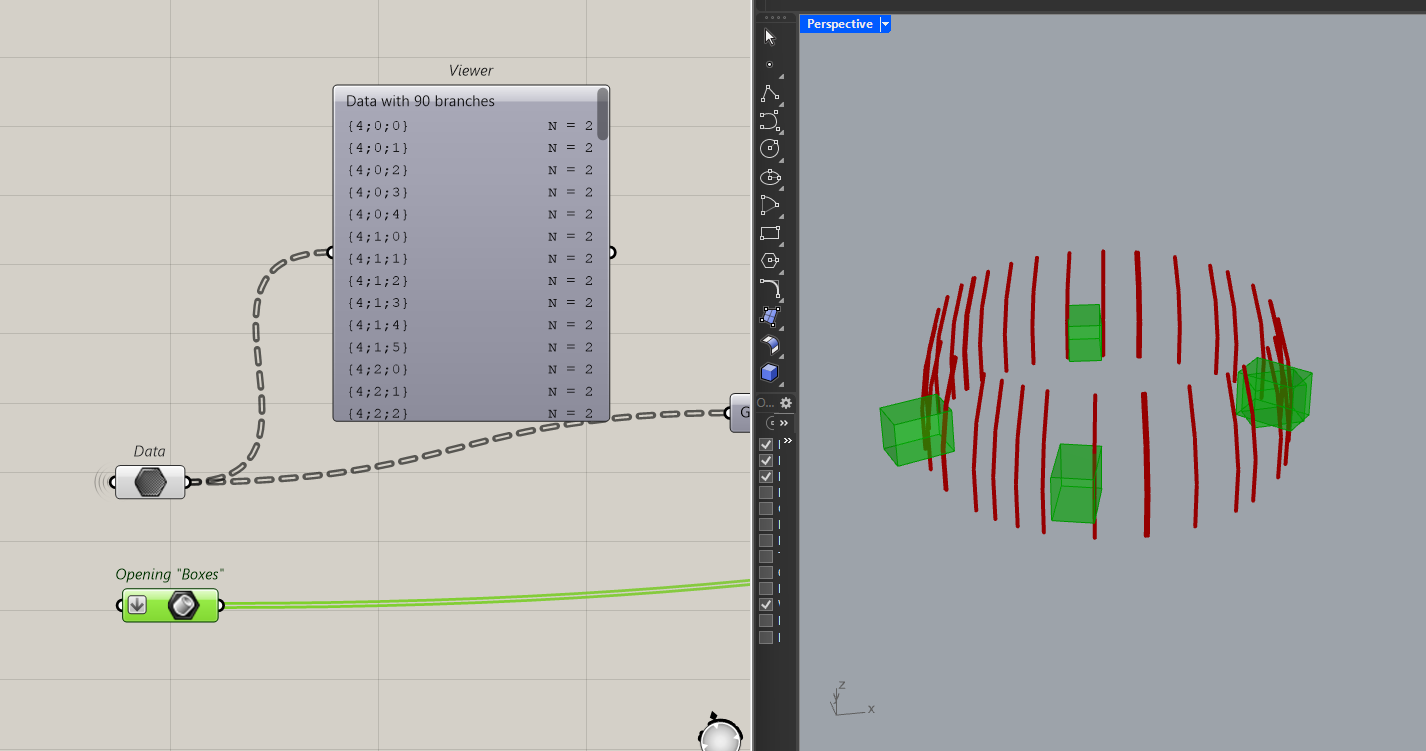
Well, I can do that by first grouping the vertical members into “bays”.
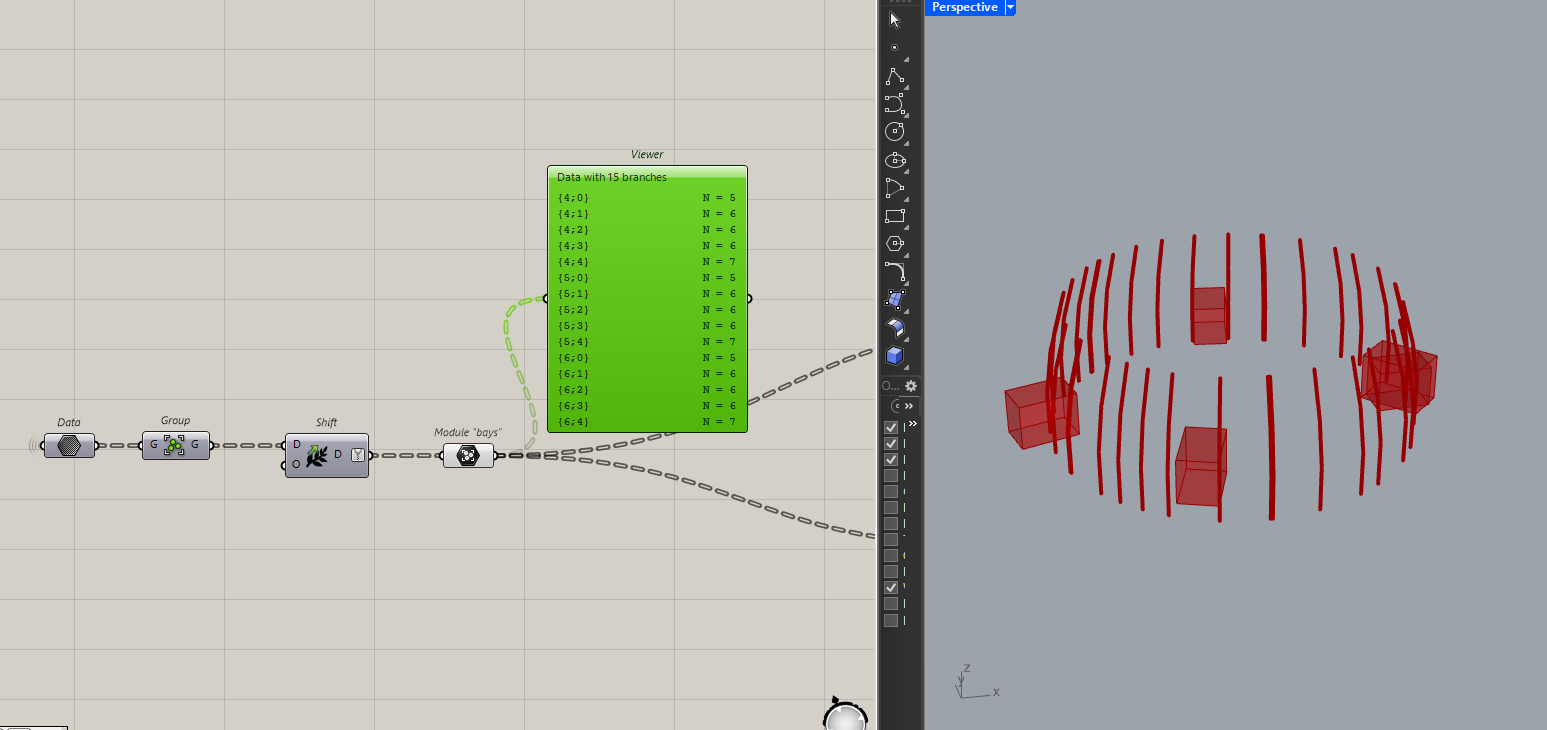
Then, get the center point of each “bay” and check if any of the boxes contain that point. If they do, I can cull the bay out.
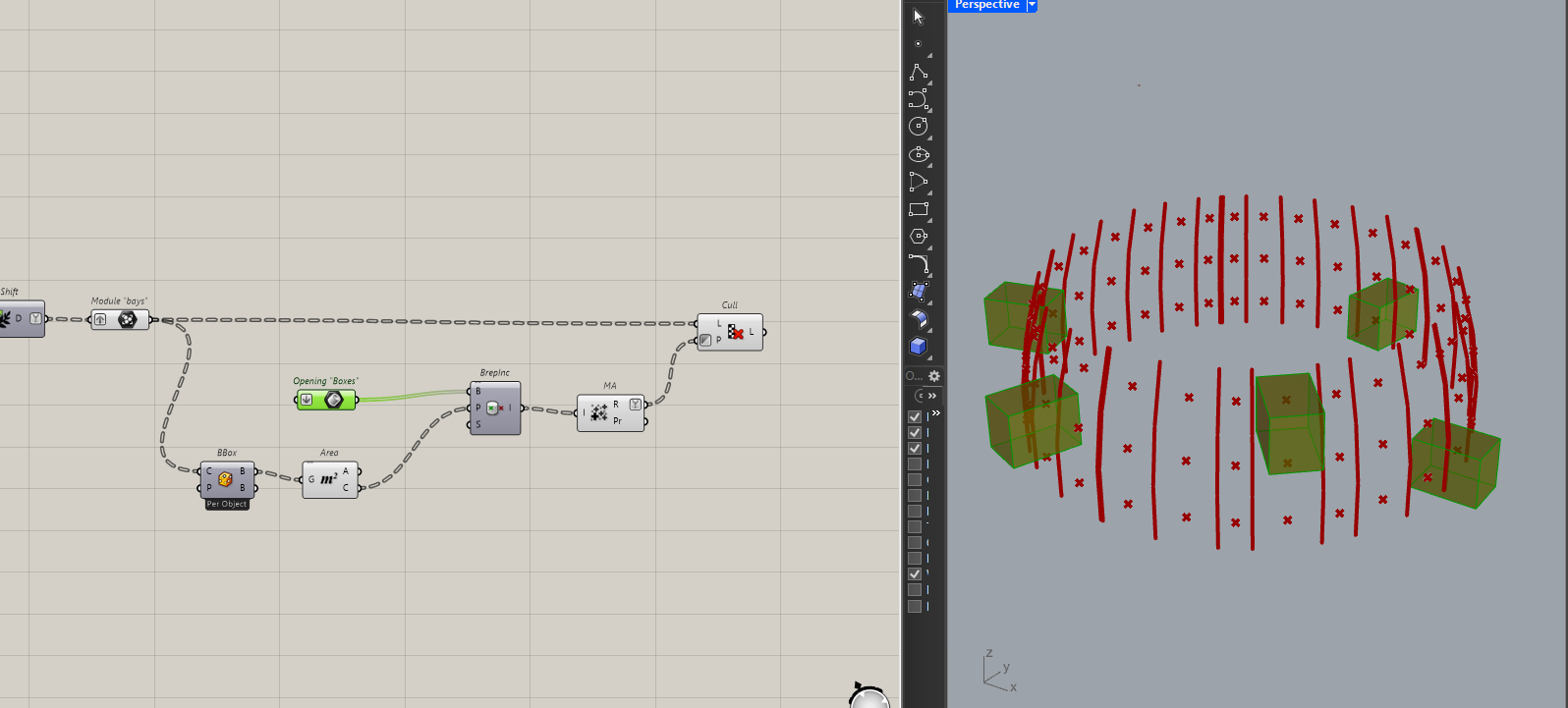
Once I have that, I can then ungroup each bay and build my diagonal members.
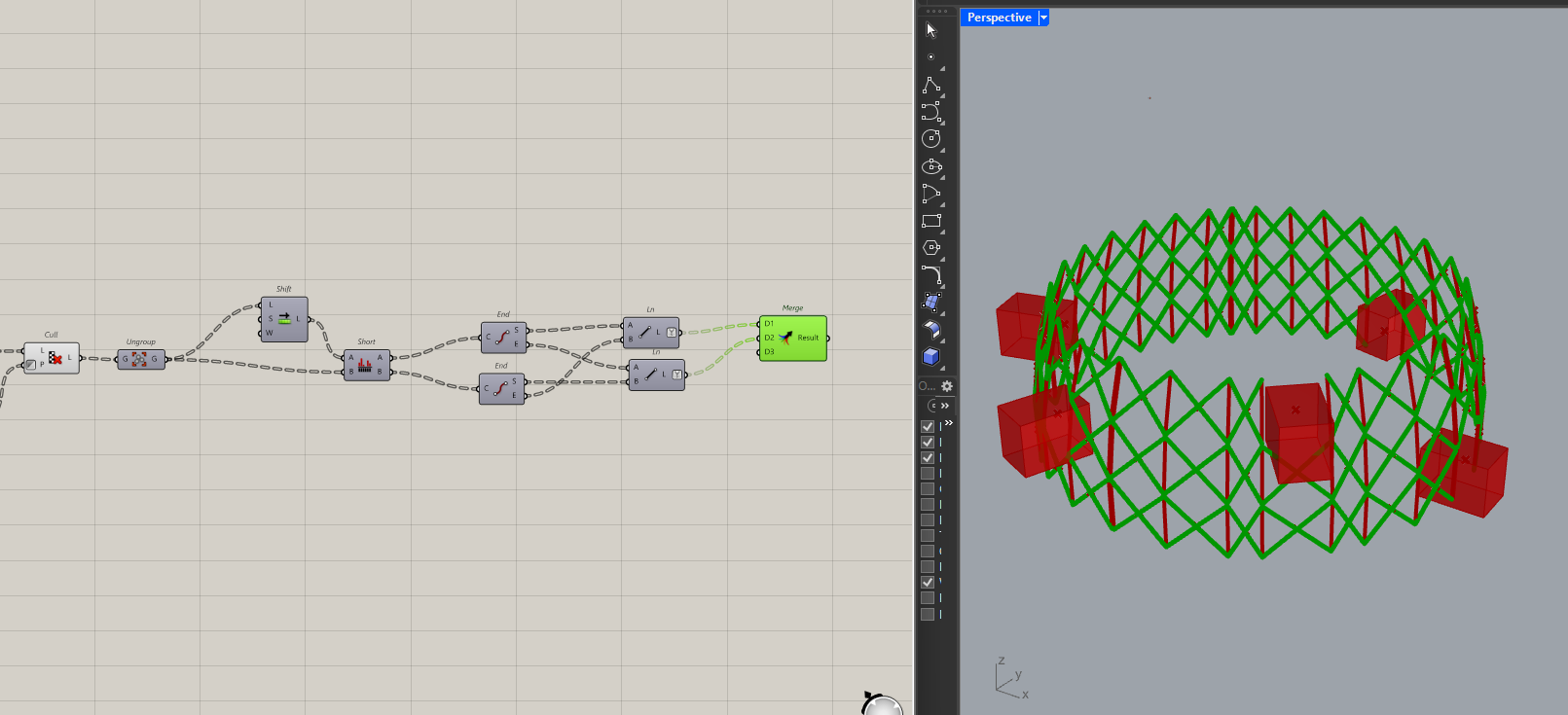
Grouping is a great way to simplify logic without destroying your overall structure. This helps create some flexibility in the way you work with data-trees.
Branching by property
On a similar note, if your original tree structure is too rigid, you can rebuild it based on a property in each item. Think of it like a re-grouping of your data. We can do this with the create tree component from the Elefront plugin.
First, we need to identify a property we want to group by.
For an example, I have a list of boxes in my model that can be grouped radially. I can get the property of each item in my data-tree by getting it’s centroid and then it’s polar coordinate, the property I want the radial angle.
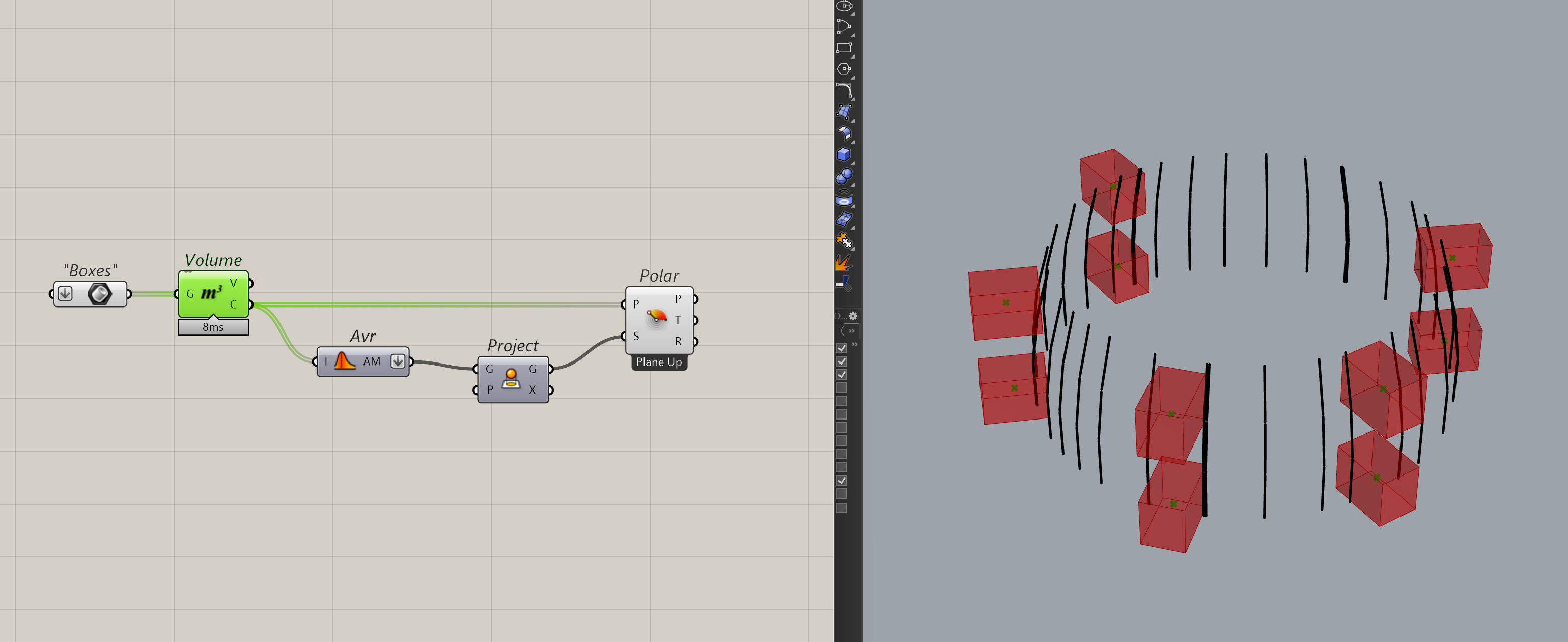
Then, I’ll use the Cset component to make a set of the property. You can also use this chance to sort your property. (e.g. sorting by elevation). Since I am doing this radially, I don’t have to sort.
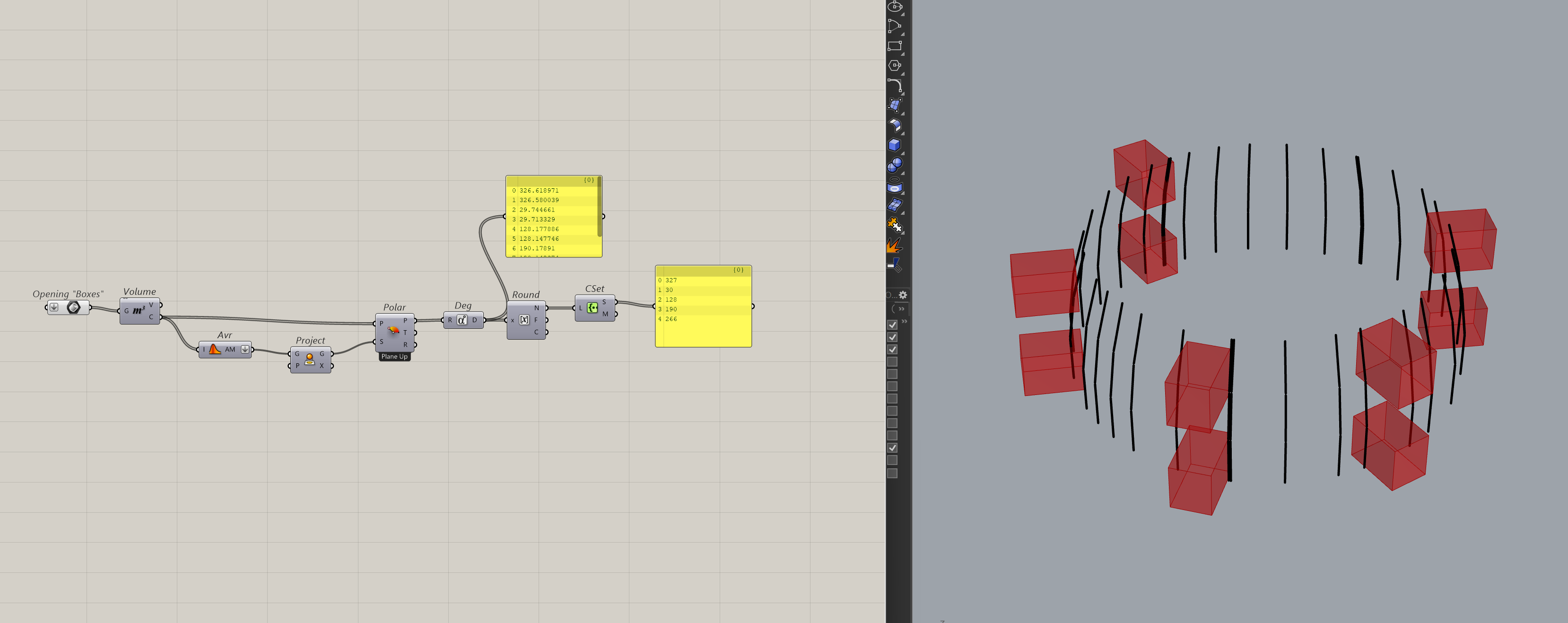
At this point, it doesn’t really matter what the values are as long as they are distinct enough to be grouped. For the next step, I’ll use the member index component and pass in the set and the list of properties from before. This component returns a list of indices based on your set from the original list.
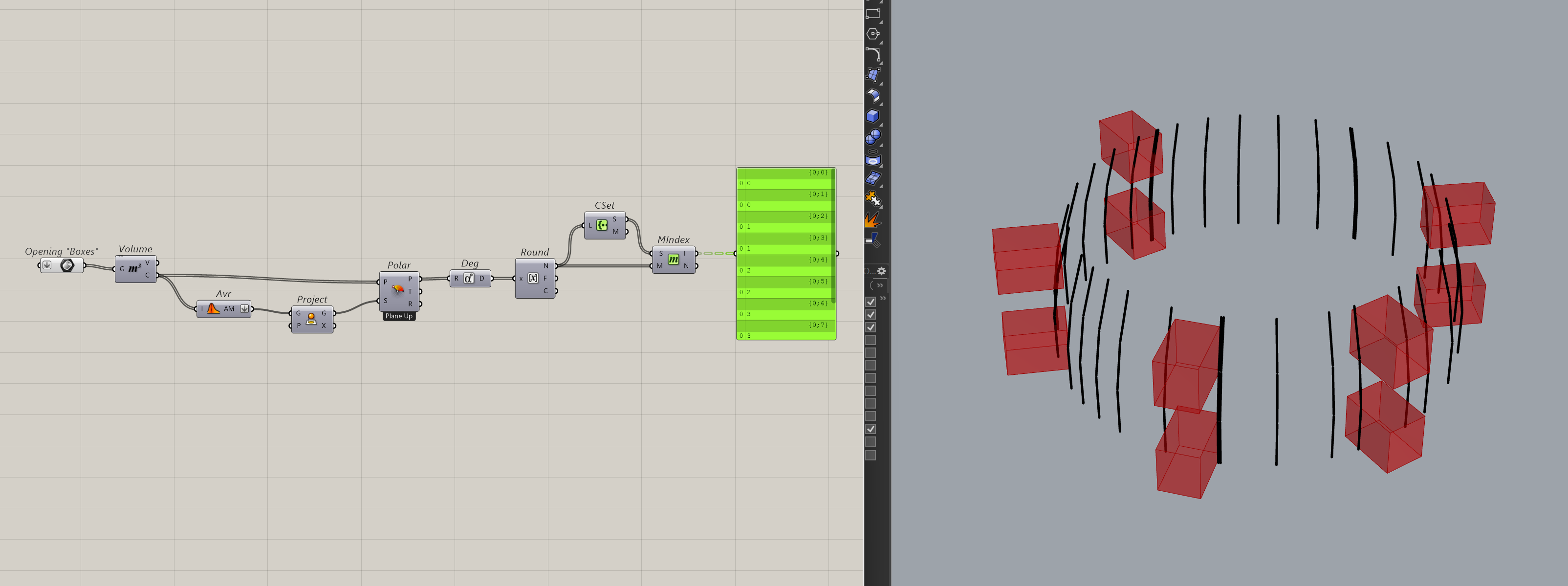
The indices are actually our new tree paths. And by using the create tree component, we can create a new data-tree where each branch is grouped by the set that you passed in. This is what my data now looks like.
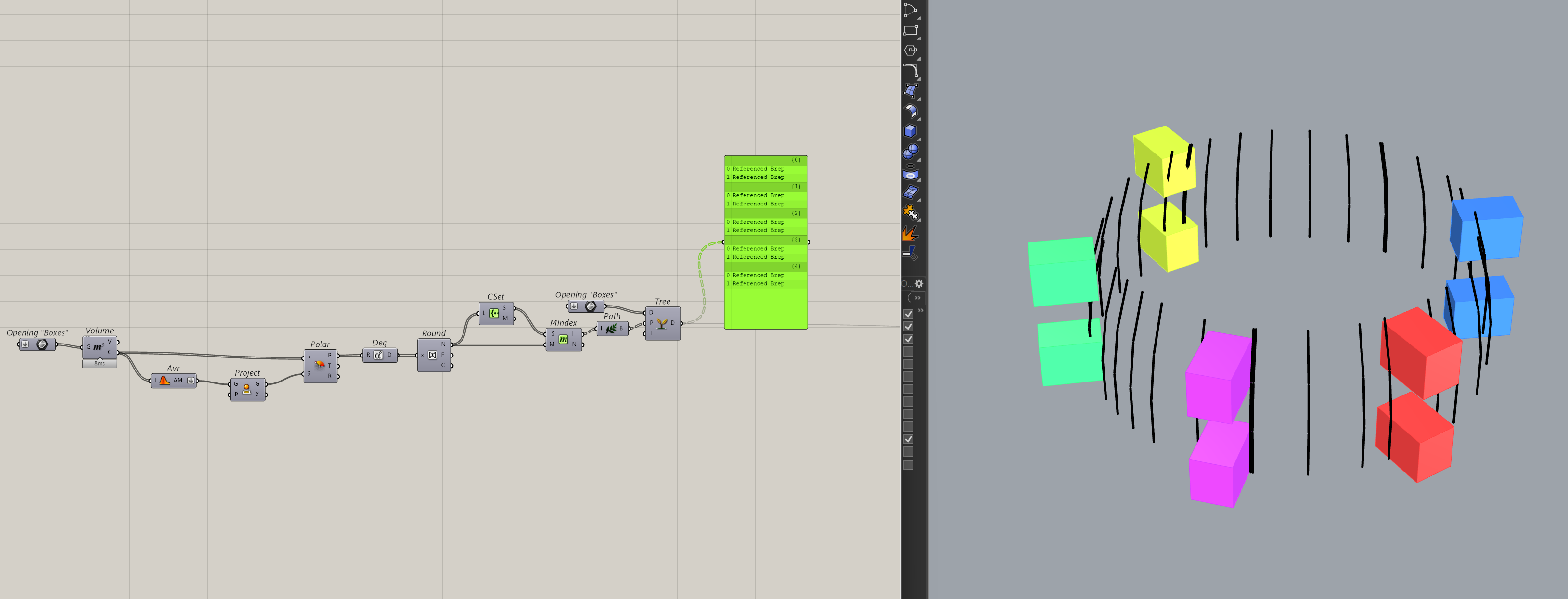
You can do this with any kind of property. Elevation, distance, angle, etc... The idea is to find something your items have in common and then re-structure your data based on that.
Principles of data-tree manipulation
Okay, those are the common ways I use data-trees in my scripts. A lot of times, I find it hard to explain data-trees because it always comes with a complex setup at the beginning, so hopefully that wasn’t too confusing.
To master data-trees comes down to experience and resisting the urge to just copy and paste existing workflow. The next time you come across a complicated data-tree, try and wrestle it instead of doing what’s simple, it’s the only way you will learn.
That being said, techniques are important but having the right mindset also helps. Here are two principles that help me decide how to structure my data.
Balancing structure and simplicity
When it comes to working with data-trees, it always comes down to balancing simplicity against structure.
As in, create a complicated data-tree too early in your script and you’ll realize how rigid your data is. Use lists everywhere and you’ll realize how hard it is to organize your data later. The key is knowing which level of complexity to maintain at all times. This depends on how complex your script is and how much effort it takes to go “up and down” in structure.
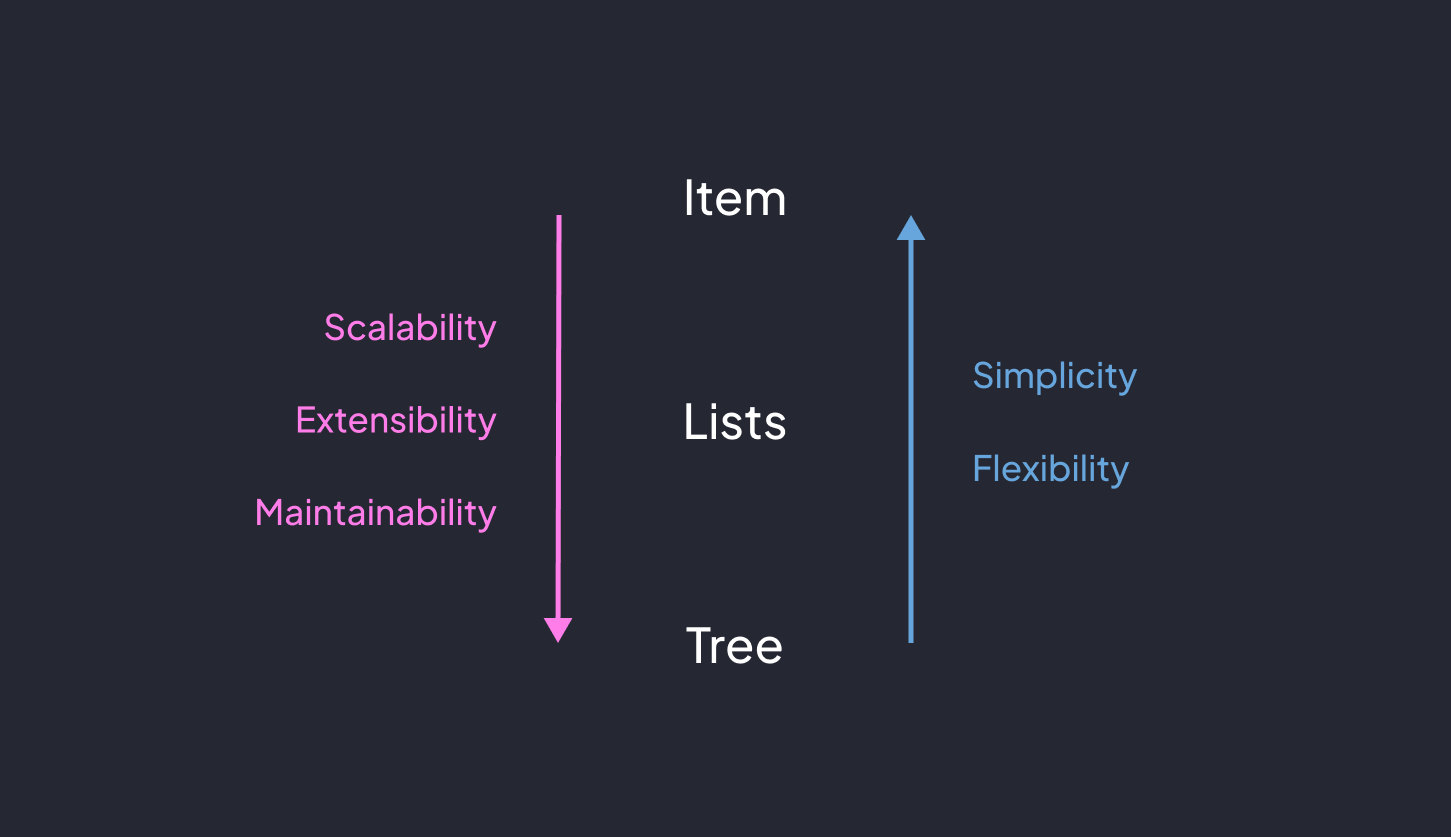
I can’t speak for every problem but the general sweet spot for me seems to be trees that are 2-3 levels deep. Any more than that and it becomes too rigid and confusing to work with.
A lot of times, it comes down the level of effort needed to recreate the structure. If it’s not much, you can forgo it, but if it costs too much, it’s better to keep that structure and use some other technique to simplify or re-organize it later. I often find myself re-creating similar structures in a script just because it’s easier than maintaining it throughout.
One for all or many to many
Another rule of thumb that I have is to minimize the amount of automatic list matching that Grasshopper does.
Just a quick recap of what list matching is. It’s when you pass in different list lengths to a component, Grasshopper won’t throw an error because Grasshopper tries to match the two lists. And when you think about how this logic applies to data-trees, it gets even more confusing and unreliable.
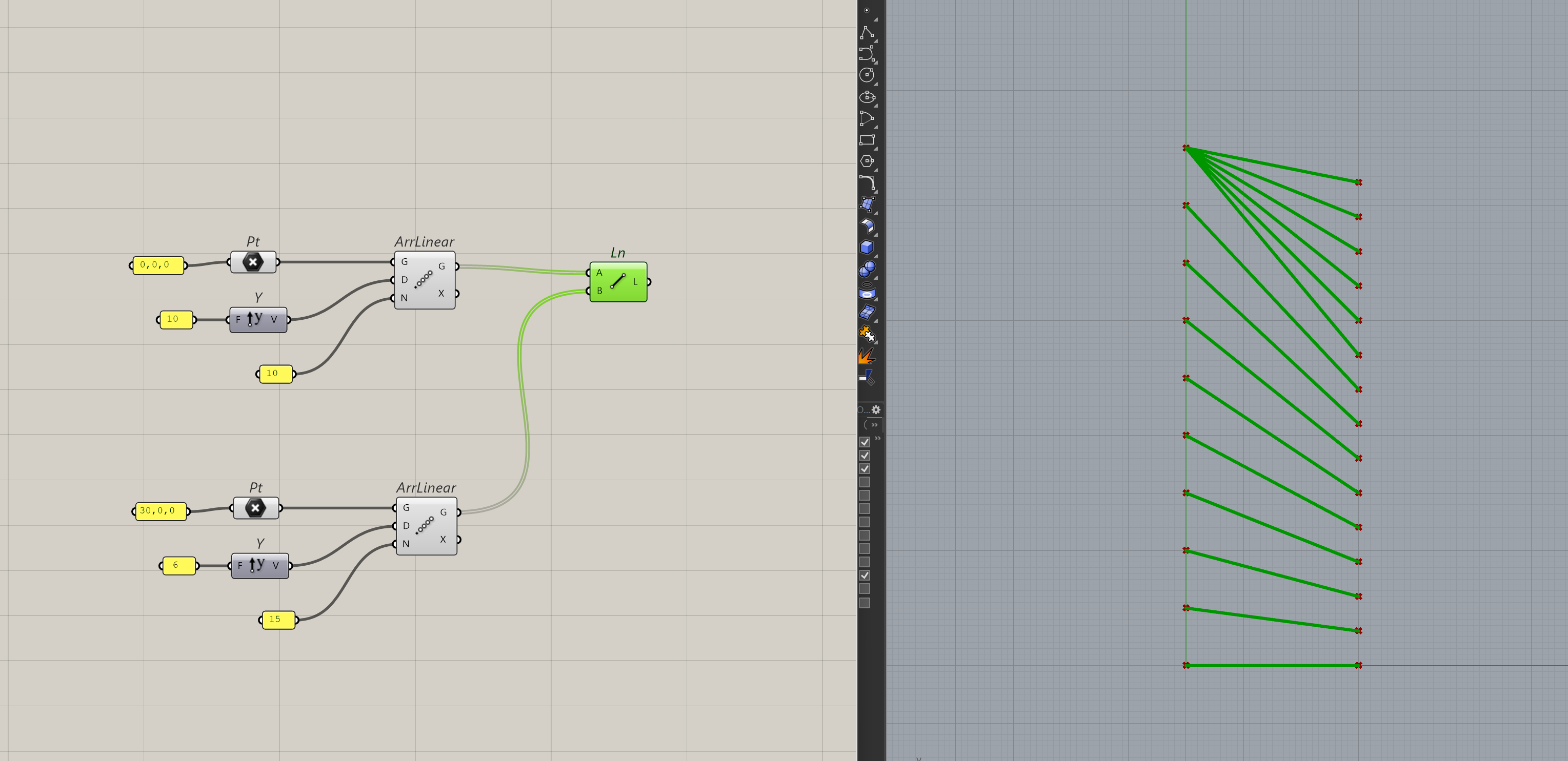
So, the best way for dealing with this, is to completely avoid it.
What this means, is to either pass in 1 item for a list or 2 lists with the same length. Nothing in-between.
Like earlier, when we took a look at merging shatter results, I grafted the input to match the data-tree structure instead of relying on Grasshopper to automatically match up the inputs.
I’ll even go so far as to process things in a certain way just to maintain the same tree-structure.
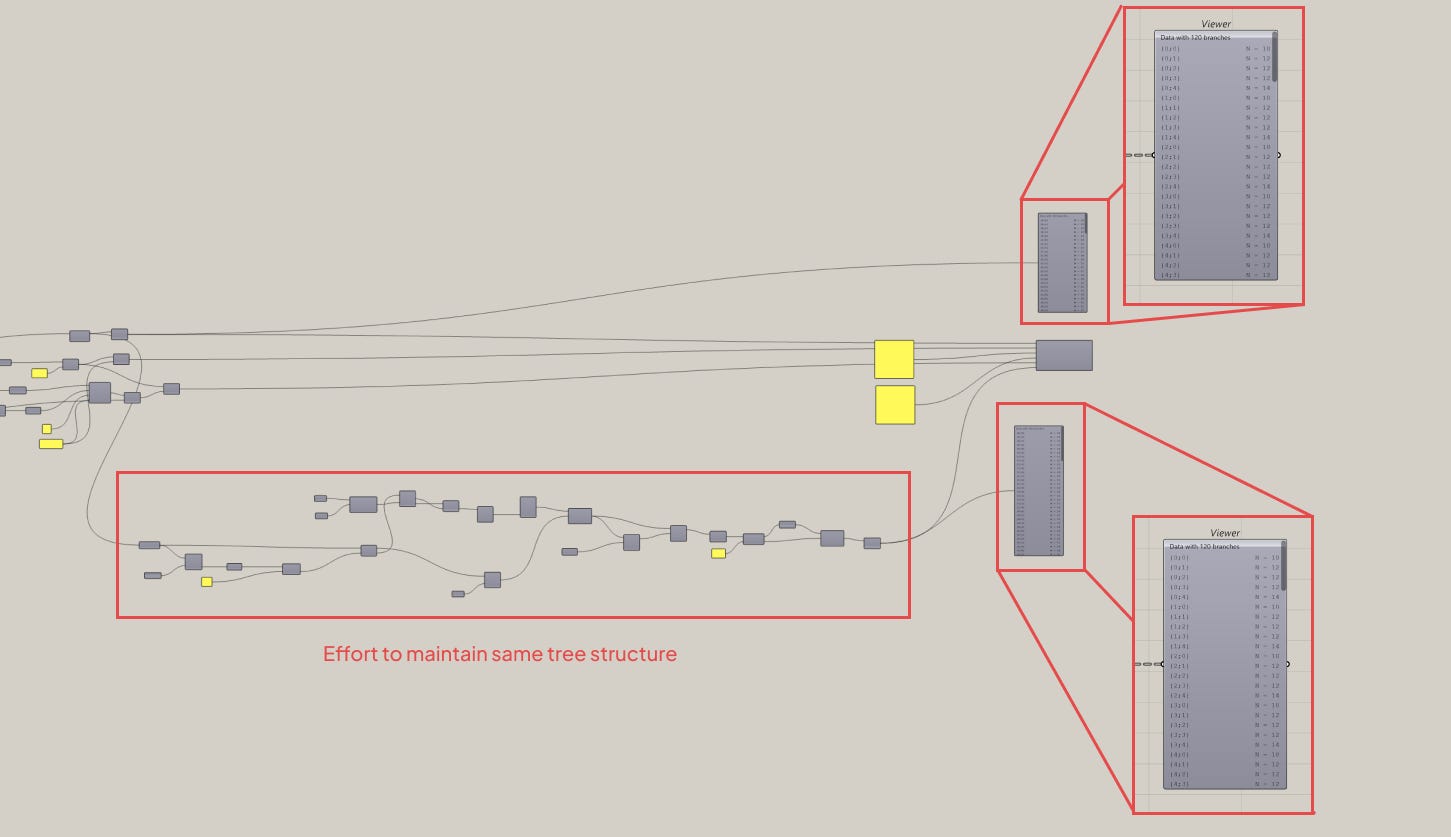
So it’s always better to manually match your data-trees with grafts and/or shifts instead of leaving it to Grasshopper. It’s more consistent, predictable, and easier to debug later on.
Final Thoughts
Phew. Okay, that was a long one. The key thing to remember with data-trees is that there isn’t one perfect structure. It’s about organizing them in a way that suits the problem you’re trying to solve right now.
And when I say problem, I don’t mean the entire script, I mean a specific part of it. I’ll re-structure my data-tree anywhere between two to ten times in a single script. Maybe I’ll organize my curves by elevation, then later re-organize them by their distance to the ground. It’s really about understanding how your data moves through the script and choosing the structure that fits the problem at hand.
Once you start paying attention to your data structure, you’ll realize that most “weird Grasshopper bugs” are actually data structure problems. More often than not, it’s because the data no longer conforms to the original setup of the script. With time and experience, you’ll start predicting these shifts and creating your trees in ways that make your scripts more robust.
Want to learn where to apply computational design?
Subscribe to CodedShapes and I’ll send you my free guide on how to actually do that
This article comes at the perfect time, making me wonder what if we apply this data tree logic to not juts Grasshopper but general AI scaling issues.