

Why Computational Design is About Searching, Not Grouping
Use the robots to find things for you


I confess. When I was hunting for "Diffusions of Innovations" the other day, I also stopped by a library to see if I could at least get a glimpse of the book. I was tired of going to bookstores and thought maybe I could borrow it for my book club session.
The library I walked into was far more organized than any bookstore I'd been to that day. Actually, I think all libraries are more organized than all bookstores. Maybe it's because they aren't trying to sell you books, they're spaces for sharing knowledge (or occasionally, doing the hanky panky in the far corners).
But it got me thinking about how libraries organize their books. I know libraries in the US use something called the Dewey Decimal System. Australia also has some libraries that use the same system. It's a way of organizing books. It saves anyone from manual sifting through all the books.
It organizes books by genre then their sub-genres. It means, if I am looking for literature book. I go to section "800 - Literature" of the library and then look for the book in it's sub-genres.
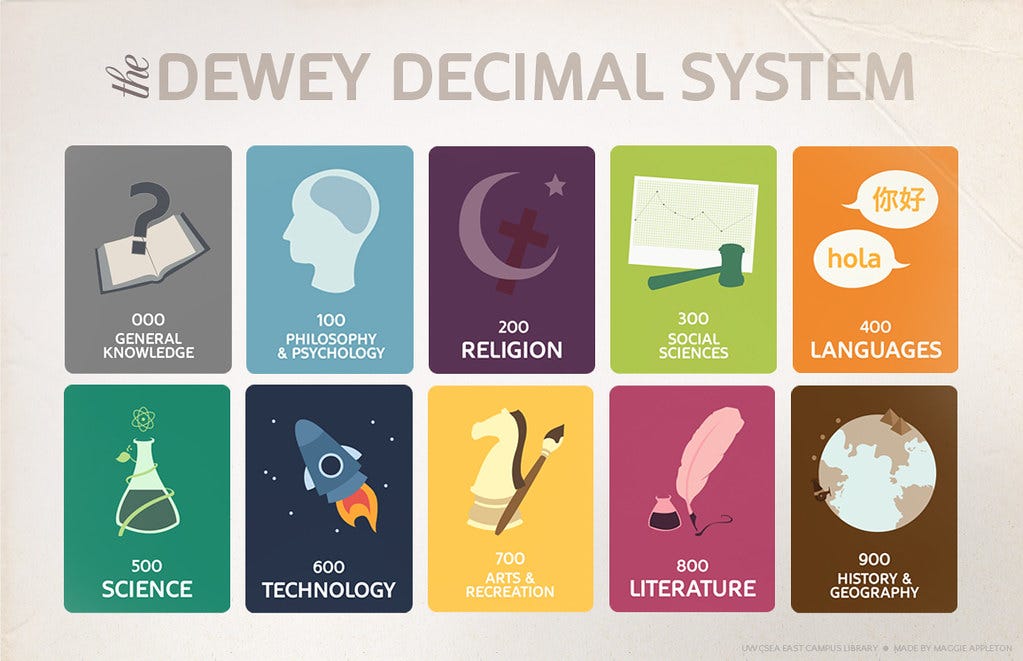
Image from : The Dewey Decimal System at LACC - Using the Library - Library Homepage at Los Angeles City College
But even this system, the system that has been used by almost every library in the US has a critical flaw. It only groups book by a single genre. If you have a book with two genres which genre do you put them in ?
The "Diffusions of Innovations" book that I was trying to find has at least two genres: technology and philosophy. So, do I go to the "100 - philosophy & psychology" or "600 - Technology" section ?. If there was 1000 books in each section, I might have to sift through all 1000 just to find out I was in the wrong section.
But this isn't the system's fault, it's the limitation of physical organization. You can only group things by one way.
The Power of Metadata (Identifying properties)
Well, in the digital world, we no longer need to put things in one place. We don't have worry about sorting books by their published year OR grouping them by genre. Digitally, you can do both. And, this is done with metadata.
So, instead of grouping books by their genre, then sub genre, the idea of metadata is to associate information to the objects that define them. For books, these might include:
Title
Author
Genre(s)
Publication date
Checkout status
Tags
ISBN
Publisher
Store Location
Language
These are all information that every book should have. Using this information we can use computers to perform meaningful searches that were impossible before. It's hard to imagine this because computers are much faster at searching than we are, they can sift through a lot of data in a matter of seconds. That removes the limitation of organizing things by a single way.
By using metadata, we introduce filtering and rule-based searching. I can now tell the computer to find for :
"All books published in 1989 that belong to the 'technology' genre AND were written by female authors"
And I would get back a list of books.
Rule-Based Searching in Computational Design
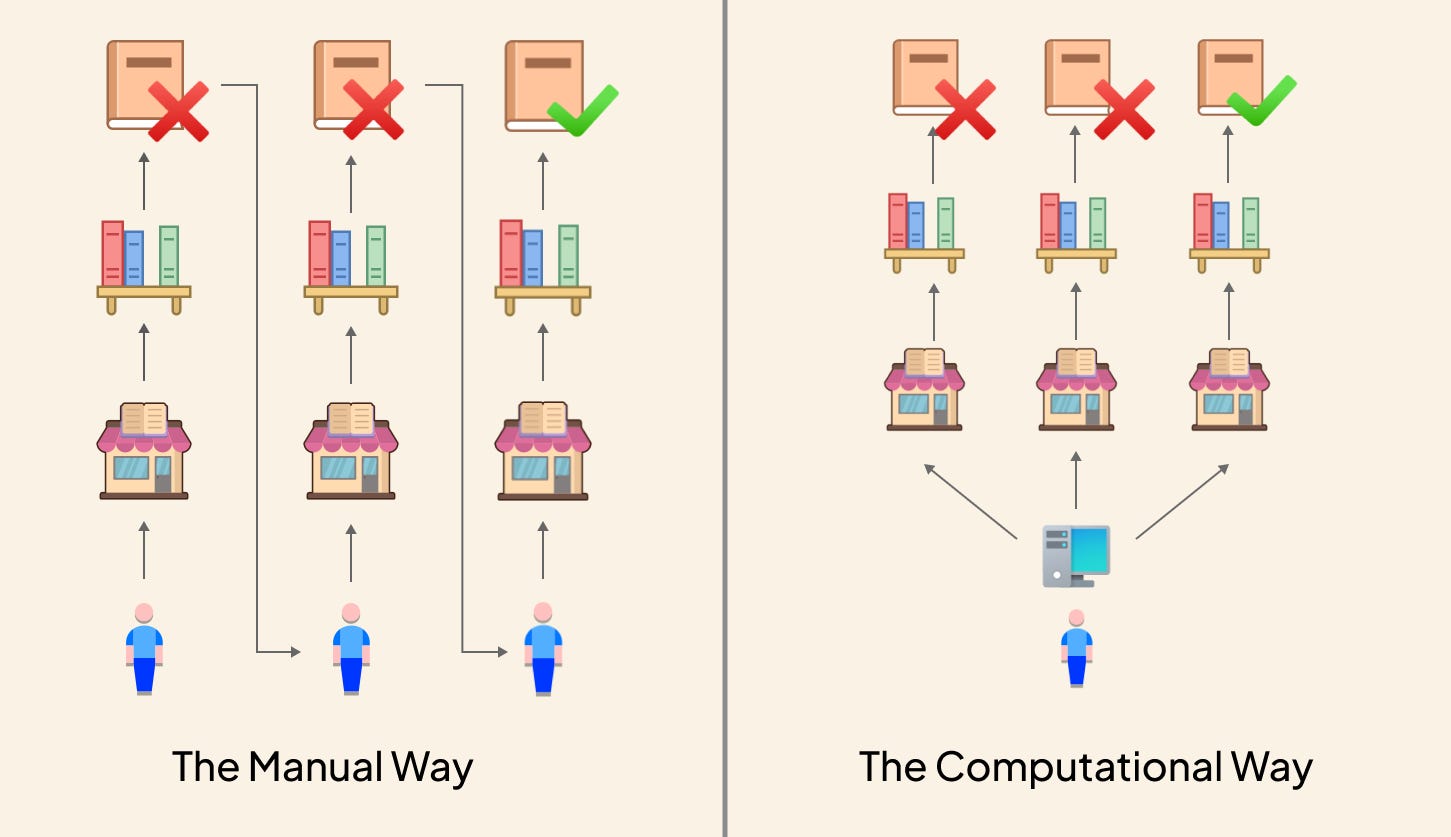
Most people don't see it this way, but you can apply the same principles to 3D models too. This is actually what computational modeling does, identifying geometry based on its properties and then performing operations on it.
Instead of worrying about how your elements are grouped. We can use scripts to identify and select elements based on their properties.
From Simple to Complex Queries
Most design programs come with basic category selection: "Give me all elements that are columns." But it becomes much harder to execute rules that are not part of these categories : "Give me all columns that are concrete AND are less than 5m high AND are only connected to Level 1."
If you're more experience with the program and project, you might have found custom to group elements. Like in Revit, people use worksets and in AutoCAD, people use layers. The more experience you are, the more patterns you identify to group things. But there will always be edge cases that are outside what you have already grouped.
But the more complex the identifier, the more logic you need to incorporate. This is where computational tools like Grasshopper, Dynamo, or custom scripts become essential.
Some Real-world examples
Here's a few real world examples of rule-based searching:
Structural Analysis: Aligning the axes of elements in an analysis model
BIM Data: Filling in data based a ruleset in Excel
Structural Design: Finding for moments around columns on a floor
Drafting: Finding and cutting elements in a model
A Mindset Shift
It's a weird shift in mindset because we are so used to organizing things based on categories. We put things on shelves, put files in folders, even our identity is some times tied to them. "I'm an engineer not an artist". The idea that things have unique identifying properties is new to us.
The shift here is moving from a category first paradigm ("Where is it stored?") to an attribute-based paradigm ("What are its characteristics?").
In traditional folder systems, you must decide in advance how to categorize something:
Is this file a "Project Document" or a "Client Communication"?
Should this model element be in the "Structural" folder or the "Construction" folder?
With rule-based searching, you don't have these constraints. The file or element can be tagged with multiple attributes and found through any of them.
Final Thoughts
There's was nothing wrong with how I found my book through systematic searching. It just took a lot longer compared to using a digital system.
Similarly with our design work, sometimes manual searching and exploration lead to unexpected discoveries and insights. There's value in "browsing the shelves" of our models occasionally. But when we need specific information quickly and reliably, rule-based search methods transform how we work. It just lets us find things quicker.
If you found this useful, consider subscribe to CodedShapes.
I’ll send you my free guide on applying computational design at work as a thank you.